
阅读前须知:本文主要梳理了Lora训练时常用的几个调度器,可能会有纰漏与错误,多为个人理解,经供参考,如有错误敬请指正!
前言
前段时间很多群友问训练lora时,优化器和学习率调度器该怎么选。一般来说就AdamW8bit+cosine_with_restarts凑合用了,但是最近我感觉这样的组合拳越来越不好用了,经常出现学了一千多步还不收敛或者是开头就跳水到0.06以下,然后一蹶不振完全不学。于是我去了解了一下几个常用的优化器和学习率调度器的区别,并写了这篇文章。
文章涉及到一部分深度学习的知识,我不是很了解深度学习,如果有错误请在评论区指正。
本文章主要分析各个调度器的特点,后半段为实测(可能不是很严谨)。下一篇文章会分析优化器,考虑到工作量,所以分成两半发布。
不出意外的话,下一篇是不同优化器搭配cosine调度器的测试。
学习率调度器 LR Scheduler
什么是学习率调度器
学习率(Learning Rate,LR)在深度学习中是很重要的参数。对于同样的数据集,学习率会影响到收敛的时机和准确率。
一般来说,较大的学习率会加快训练速度,但会导致模型不稳定和震荡。较小的学习率则会提高稳定性和准确性,但是相应的,训练的时间会很长。
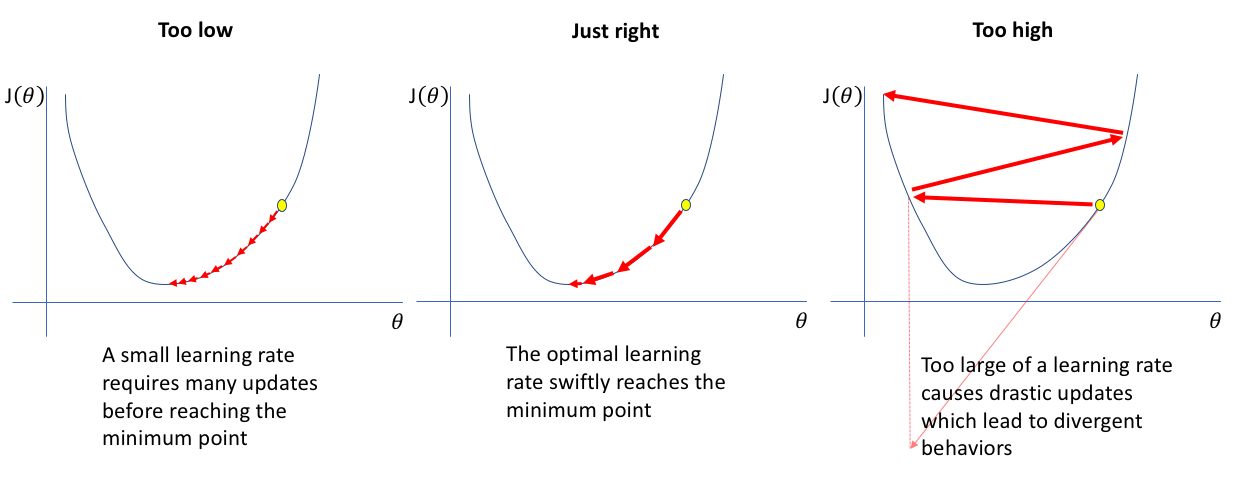
打开秋叶训练器,你会看到如下几个调度器。
本次我主要介绍如下几个调度器:
|
|
Linear 线性
对于线性的调度器,图像其实很简单,见下
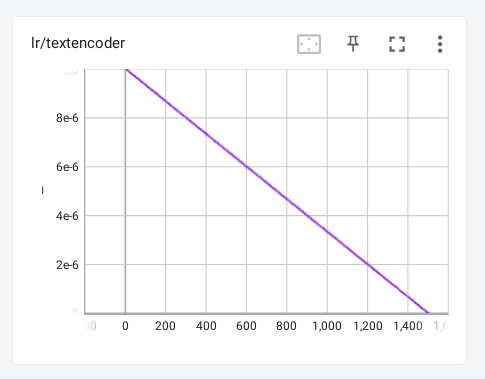
他的学习率会随着步数的增加线性下降,一般来说都不用这个调度器,因为线性的下降不一定好用,反而有过渡的余弦要好一点。当然也只是经验推测,实际效果跟余弦应该相差不大。
(可以理解为线性的太直接了,没有余弦的过渡来得自然,所以效果不太好)
cosine 余弦
余弦调度器就是学习率随着步数的增加以余弦函数的方式下降,整体图像大概是这样的。
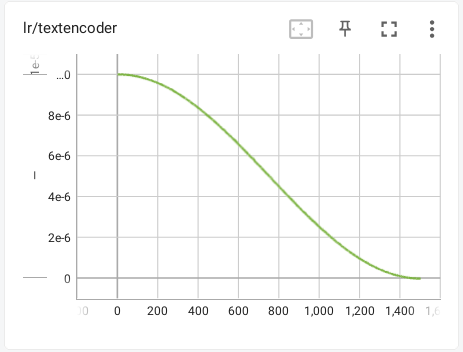
看起来他的图像是更平缓的,但是中间下降的幅度更大,同样,因为更平缓,他的拟合效果是比线性好一些的。
cosine_with_restarts 带重启的余弦
从名字就能看出,这个调度器有一个“重启”的过程,重启就是把学习率重置到参数设置的学习率然后再下降,所以他的图像相对来说抽象一点。
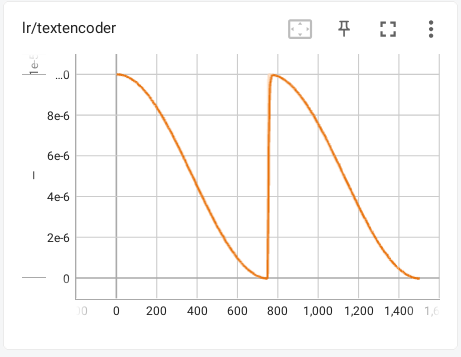
这样在中间突然提高学习率,有利于跳出局部最优解,去寻找全局最优解,所以理论上是效果最好的(我测试的时候重启次数设置为2,一般不能超过4)。
constant 常量
常量其实就是没有调度器,全程学习率不变。
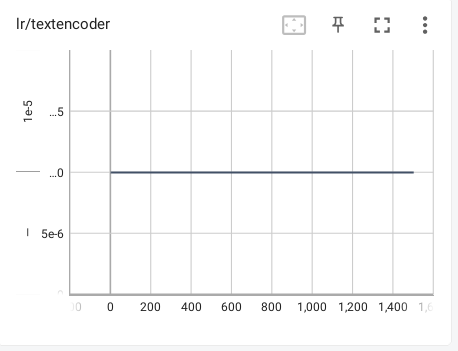
这个没什么好说的,其实这个一般搭配能调节学习率的优化器,比如Prodigy。
实测
这次实测使用的数据集是上次霞泽美游的训练集,一共15张图片,10轮总共1500步,打标时删去了特征,优化器是AW8bit。先来看看概览吧。
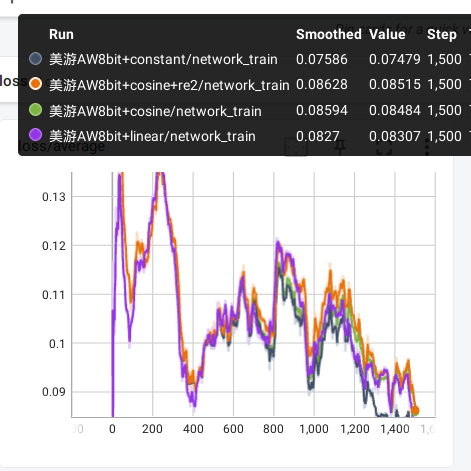

(我不太会用xy图表,请忽略掉多余的部分)
我觉得总体来看,cosine和cosine_with_restarts都还不错,而线性看起来粗糙一点,常量组的图片甚至有点过拟合的感觉。
总结
根据目前实测,cosine和cosine_with_restarts都挺不错的,可以都试一下,我觉得重启更具有功能性,对于难练的数据集可能更好用。
参考文献
感谢以下文献及其作者🙏。
|
|