
阅读前须知:本文旨在指导新进炼丹师通过我提供的素材练出第一颗丹,文中会掺杂个人理解,如有疑问可联系我。
需要下载的资源:秋叶训练器和Anby训练集(未裁剪 )
什么是Lora
Lora的全称是Lora: Low-Rank Adaptation of Large Language Models,可以理解为stable diffusion(SD)模型的一种插件,和hyper-network,controlNet一样,都是在不修改SD模型的前提下,利用少量数据训练出一种画风/IP/人物,实现定制化需求。
但是Lora所需的训练资源比训练SD模型要小很多,非常适合社区使用者和个人开发者。Lora最初应用于NLP领域,用于微调GPT-3等模型(也就是ChatGPT的前生)。由于GPT参数量超过千亿,训练成本太高,因此Lora采用了一个办法,仅训练低秩矩阵(low rank matrics),使用时将LoRA模型的参数注入(inject)SD模型,从而改变SD模型的生成风格,或者为SD模型添加新的人物/IP。
― 知乎, 什么是LoRA模型,如何使用和训练LoRA模型?你想要的都在这!
太长不看:Lora在启用后会“夺舍”原本模型里的一些参数,让他们成为lora里的“样子”,从而使微调大模型成为可能。
开始训练你的第一个Lora吧
Part 1 环境准备
截止目前能在Win下炼丹的还是只有N卡,虽然WSL支持调用AMD显卡进行训练,但是还是太折腾了,咱目前不讨论这个。
安装CUDA
首先你需要打开cmd或powershell,输入nvidia-smi查看自己的显卡所支持的CUDA版本,这个版本一般跟驱动挂钩。
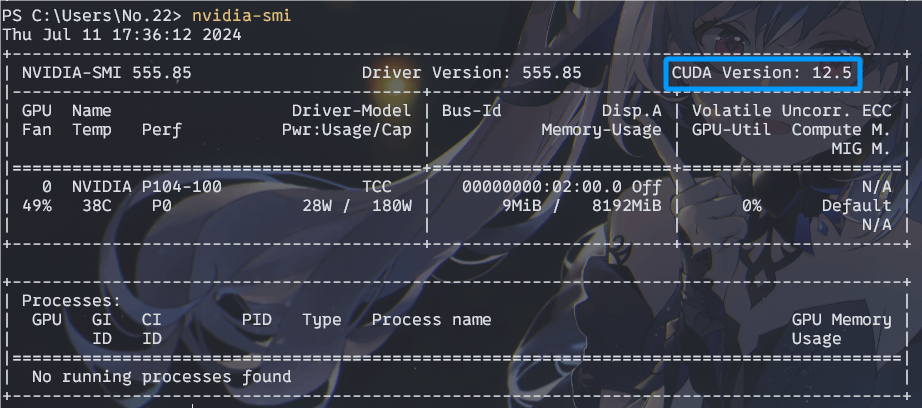 图中可以看出,我这最高支持的版本是12.5。训练所用到的torch一般要求CUDA11.8。所以只要这里显示的数字大于等于11.8就行。
图中可以看出,我这最高支持的版本是12.5。训练所用到的torch一般要求CUDA11.8。所以只要这里显示的数字大于等于11.8就行。
如果符合要求,就下载CUDA安装包,一般下载符合你的显卡的最新版本。
下载完成直接安装就行,安装完成后可以在cmd或powershell中输入nvcc -V来测试CUDA是否安装成功。

像这样能输出CUDA版本的就是安装成功了。
开摆,使用秋叶训练器!
如果你打算自己部署Kohya训练器,那么请另寻教程吧(我自己部署的Kohya训练器跑不起来)。
本人更推荐使用秋叶训练器(其实内核就是Kohya),我传了一份在123云盘,下载并解压后双击A强制更新-国内加速.bat脚本升级至最新即可。
如果升级没有出问题,就可以双击A启动脚本.bat启动训练器了。别急,训练Lora的旅程才刚刚开始。
Part 2 训练集的准备
训练集是Lora训练的基础,对Lora质量的影响处于第一位。所以拥有好的训练集是极其重要的。
角色的选取
本次我们训练的角色是绝区零的安比。我在训练二次元人物的lora时一般准备15张图片。其中画师图片(多来源于Pixiv)占大头,当然也有官方立绘和游戏实机截图。

图片尺寸的裁切
在准备好了图片后,就需要对图片进行裁剪,对于1.5模型的Lora,图片尺寸大多为512*512,512*768和768*512。这意味着我们的训练集的图片也因当裁切为这个大小。
这里我推荐大家使用birme来对图片进行批量裁切,打开后在右下角就可以设置宽度和高度了。

如果你按照我的教程一步一步来,那么现在你应该已经准备好了训练集和训练器了。你需要保证你的训练器可以正常打开,命令行里无报错,训练集的图片均裁剪成了宽512高768的。然后我们就可以调整参数开始训练了。
Part 3 对训练集的图片进行打标
打标的方式
在训练Lora模型时,打标的作用是让AI理解并学习特定的特征或属性,从而在生成图像时能够准确地映射到对应的特征上。
1.过拟合风险:仅唤起»删特征>全标>正则化
2.拟合能力(对人物的学习速度/出成品速度):全标≈=仅唤起≈=删特征»正则化
3.细节能力(非人物细节,如光环,绣肩,佩洛洛背包,画风等):正则化≈>全标>删特征>仅唤起
4.还原性(人物+衣服/全标;拟合后):无明显差别
5.易调用性: 仅唤起 > 删特征 > 全标»正则化
6.泛化能力:正则化»全标>删特征»仅唤起
― bilibili, lora干货!新手小进阶(上)!三种打标方式对比及正则化对人物训练作用讨论
补充一个小知识点:一般训练Lora会额外加一个大模型中没有的单词作为唤起词,又名触发词。一般人物Lora会将人物的名字作为触发词,比如这次我就将Anby作为触发词,添加到打标出的txt里了。
这里我们重点关注拟合能力和泛化能力,可以看到其实全标是最均衡的方案(正则化难度较高暂不考虑)。
全标,顾名思义就是对训练集中所有的元素都进行标记,这样AI就会学习到每个元素的特征,因此不仅泛化能力好,细节也能还原。
而全标的另一个极端便是仅唤起,简而言之就是不论是哪张训练集图片,都只对应着一个tag,也就是此次训练的触发词。这样AI便会把所有的元素都塞进这个触发词中,所以易调用性是最好的,但是却舍弃了(几乎全部)泛化性。萌新别学!
开始打标吧!
打标一般依托于一些插件,常用的打标方式有BLIP,DeepBooru和WD1.4。秋叶训练器中集成了一个WD1.4打标器,所以我们就使用WD1.4插件来对训练集进行打标吧。
Tips:为了方便整理和训练,我强烈建议各位创建一个文件夹来储存训练集。例如:D:\Lora\Anby训练集\Anby。其中,Anby训练集文件夹中放的是未经裁剪的图片,Anby文件夹中则放裁剪后,统一了尺寸的图片。
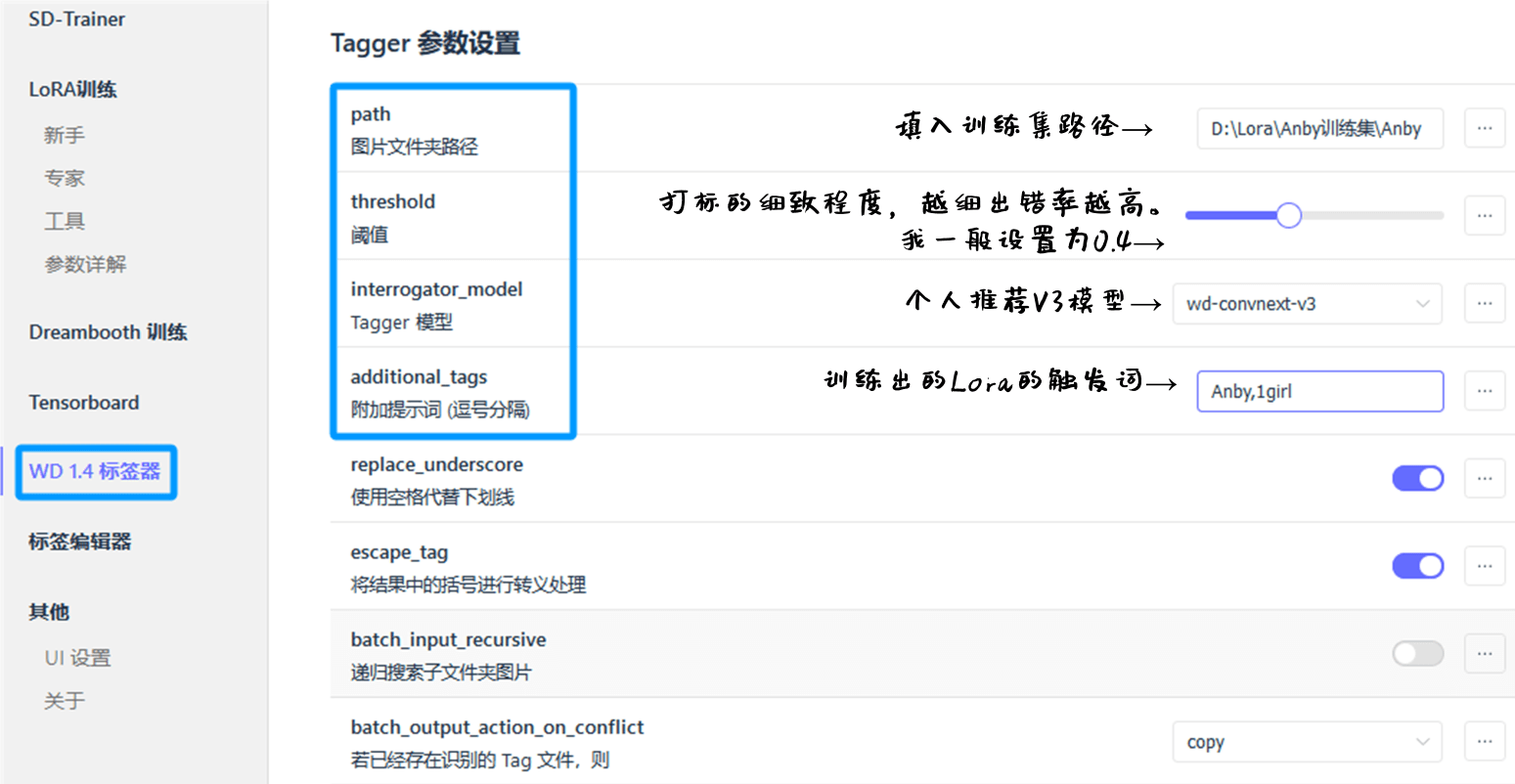
在训练器的页面,进入WD1.4的打标页面,设置路径,阈值,模型,触发词,就能单击右下角开始打标了。
打标完成后可以在命令行看到输出。在我们的训练集目录里,应该长这样:
对标签进行清洗
通过对自动标注的Tag标签进行清洗,可以确保模型学习到准确的信息,从而提高最终生成图片的质量和准确性。本次我们采取全标的打标方式,那么我们只需要删除错标的tag就行。
转到训练器的“标签编辑器”页面,按照下图,可以在右下角看到所有的标签,删去错标的标签即可。
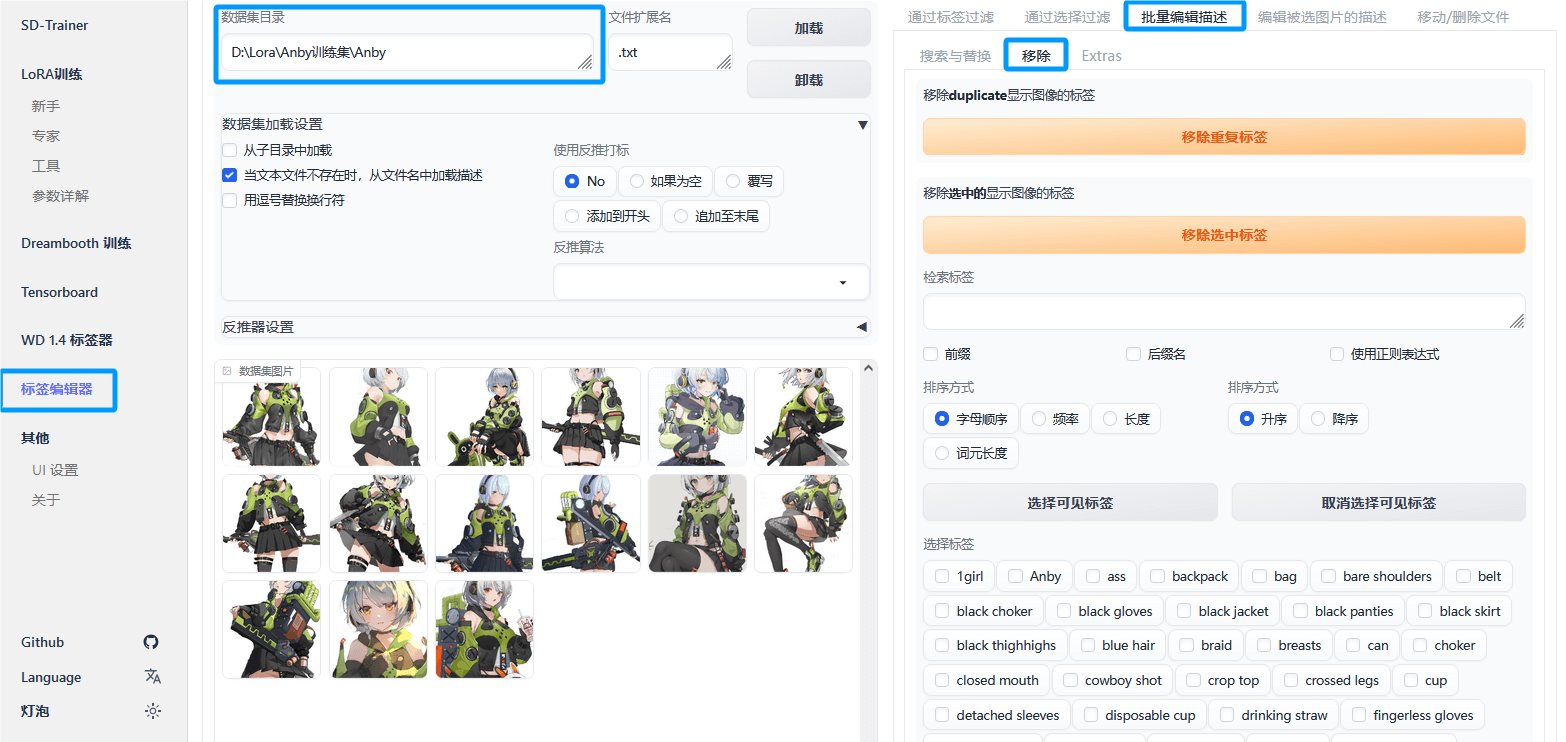
最后需要单击此页顶端的“保存所有更改”,不要忘了哦。
Part 4 调参并开始训练
笼统设置
Lora训练的参数浩如烟海,但是本次我们不涉及太多的参数,请转到训练器的专家页面,详细调整可见下图。
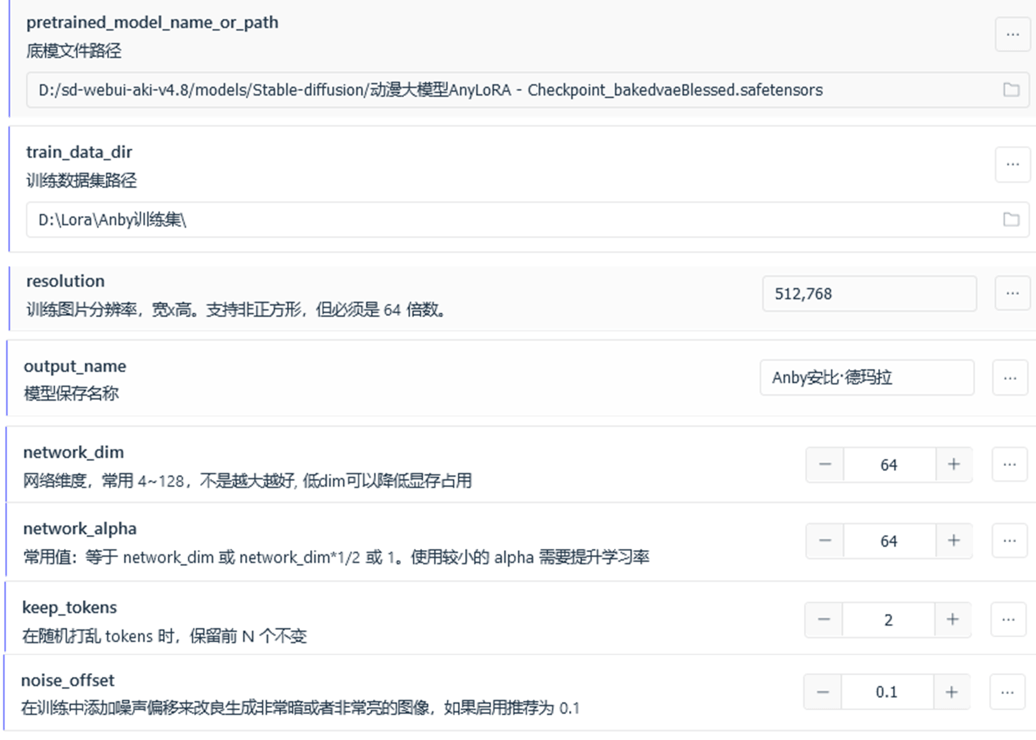
下面我来对这些参数做一个简单的阐述。
|
|
训练步数设置
Lora训练中,训练步数决定了AI将学习多少次你的训练集。在训练器中max_train_epochs参数决定了训练的轮数。而你的训练集路径D:\Lora\Anby训练集\10_Anby中的10决定了每张图片学习的次数。由此,可以通过一个简单的公式算出此次训练的总步数。
轮数*次数*训练集图片数=总步数,也就是10*10*15=1500步
一般二次元Lora只需要1500~3000步,而真人就需要5000步以上了。我训练的几次都是1500步,自我感觉良好。
补充
这些设置比较看显卡,大家酌情调整。
|
|
Part 5 开始训练
如果你按照本教程,那么现在应该已经调好了参数,可以开始训练了。
现在请怀着敬畏的心,单击右下角的开始训练
等待命令行里出现这样的输出,就说明训练已经开始,可以转到训练器的TenserBoard,监测本次训练的Loss值了。
|
|
Loss值是指模型预测结果与实际目标之间的差异度量,一般在0.06~0.08之间都是比较好的结果。但是也要看跑图的质量,Loss值不能作为Lora质量的全部体现
收工!
训练结束后,你应该可以在训练器的.\output目录下找到输出的Lora,有的后面有的会有-00000X的后缀,这是训练过程中保存的Lora。考虑到我们只跑了1500步,所以没有这个后缀的成品Lora(练满1500步的)应该会有一个比较好看的Loss值。你可以将其复制到SD的Lora文件夹下使用它,不过不要忘了加上触发词哦。